(Also available in Pyret)
Students learn about random samples and statistical inference, as applied to the Animals Dataset. In the process, students get a light introduction to the role of sample size and the importance of statistical inference.
Lesson Goals |
Students will be able to…
|
Student-facing Lesson Goals |
|
Materials |
|
Preparation |
|
- statistical inference
-
using information from a sample to draw conclusions about the larger population from which the sample was taken
🔗Flip the Script: Inference v. Probability 45 minutes
Overview
Statistical inference involves looking at a sample and trying to infer something you don’t know about a larger population. This requires a sort of backwards reasoning, kind of like making a guess about a cause, based on the effect that we see. To better understand the process of going from the sample back to the population, it helps to understand the more straightforward process of going from the population to a sample. If the sample is random, we call this process Probability!
In real life we typically don’t know what’s true for an entire population. But this probability thought-experiment will start with a larger population with known properties (such as the fact that nearly half of the entire population are males). Then we’ll see what kind of behavior we tend to see in random samples taken from that population.
Launch
Inference Reasons Backwards; Probability Reasons Forwards
One of the most useful tasks in Data Science is using sample data to infer (guess) what’s true about the larger population from which the sample was taken. This process, called statistical inference, is used to gain information in practically every field of study you can imagine: medicine, business, politics, history; even art! Early on, statisticians discovered that random samples almost always work best.
Suppose we want to estimate what percentage of all Americans plan to vote for a certain candidate. We can’t ask everyone who they’re voting for, so pollsters instead take a sample of Americans, and generalize the opinion of the sample to estimate how Americans as a whole feel. But choosing a sample can be tricky…
-
Would it be problematic to only call voters who are registered Democrats? To only call voters under 25? To only call regular churchgoers? Why or why not?
-
How could we choose a representative subset, or sample of American voters?
-
Would it be problematic to only sample a handful of voters? What do we gain by taking a larger sample?
Before we infer something unknown about a population from a sample, we need to know what makes a "good" sample!
Sampling is a complicated issue. The main reason for doing inference is to guess about something that’s unknown for the whole population. But a useful step along the way is to practice with situations where we happen to know what’s true for the whole population. As an exercise, we can keep taking random samples from that population and see how close they tend to get us to the truth. Another discovery (besides the value of randomness) that statisticians made early on was something that’s perfectly consistent with common sense: Larger samples are better than smaller ones, because they tend to get us closer to the truth about the whole population.
Let’s see what happens if we switch from smaller to larger sample sizes, if we’re taking a random sample of shelter animals to infer what’s true about the larger population…
Students should open Animals Dataset - Full population.
Investigate
The Animals Dataset we’ve been using is just one sample taken from a very large animal shelter. We’re going to analyze which is better at guessing the truth about an entire population - a small sample of 10 randomly selected animals, or a large sample of 40 randomly selected animals.
Select Sampler from the Plugins dropdown menu.
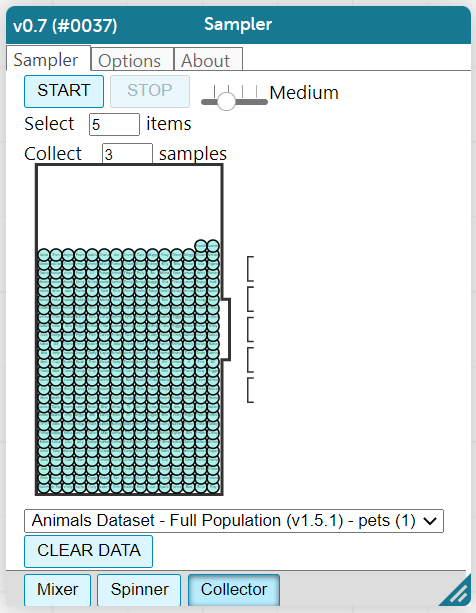
The Sampler plugin features a Mixer, Spinner, and Collector. Today, we’ll be using the Collector, which chooses a specified number of cases from a dataset.
What do you notice about the Sampler? What do you wonder?
Possible wonderings include: How many turquoise balls are there? Why is there that amount? How many brackets are alongside the collection of turquoise balls? Why are there that many?
-
Select the
Optionstab of theSampler. -
Which makes the most sense for our dataset: collecting cases with replacement or without replacement?
Note: If a particular animal can be selected more than one time, then we are sampling with replacement. In a drawing-names-from-a-hat scenario, we’d return each name to the hat after selecting it. If a particular animal can be selected only one time, then we are sampling without replacement. In a drawing-names-from-a-hat scenario, we’d remove each name from the hat after selecting it.
-
Designate the number of items to select and the number of samples to collect.
-
What would it mean to select three samples of five items each? (These are CODAP’s default settings.)
-
Enter the correct specifications for 1 collection of 10 items.
-
Click
Startto observe the sampling simulation.
After the simulation is complete, a hierarchical table (titled experiment/samples/items) will be populated. Ensure that students understand all the components of the new table they’ve created.
-
Rename the table (by clicking on its title)
small-sample.
Now that students are comfortable using the Sampler, it’s time to dig into the data.
-
Divide the class into groups of 3-5 students.
-
Let students know that they want
large-sample(on the worksheet) to be its own unique table. To produce a new table usingSampler, reopen the plugin rather than simply modifying the number of items. -
Have students complete Sampling and Inference, sharing their results and discussing with the group.
Common Misconceptions
Many people mistakenly believe that larger populations need to be represented by larger samples. In fact, the formulas that Data Scientists use to assess how good a job the sample does is only based on the sample size, not the population size.
Extension In a statistics-focused class, or if appropriate for your learning goals, this is a great place to include more rigorous statistics content on sample size, sampling bias, etc. |
Synthesize
Have students share. Were larger samples always better for guessing the truth about the whole population? If so, how much better?
Project Options: Food Habits / Time Use In both of these projects, students gather data about their own lives and use what they’ve learned in the class so far to analyze it. This project can be used as a mid-term or formative assessment, or as a capstone for a limited implementation of Bootstrap:Data Science. See the project descriptions for Food Habits and Time Use. (Based on the projects of the same name from IDS at UCLA) |
These materials were developed partly through support of the National Science Foundation,
(awards 1042210, 1535276, 1648684, and 1738598).  Bootstrap by the Bootstrap Community is licensed under a Creative Commons 4.0 Unported License. This license does not grant permission to run training or professional development. Offering training or professional development with materials substantially derived from Bootstrap must be approved in writing by a Bootstrap Director. Permissions beyond the scope of this license, such as to run training, may be available by contacting contact@BootstrapWorld.org.
Bootstrap by the Bootstrap Community is licensed under a Creative Commons 4.0 Unported License. This license does not grant permission to run training or professional development. Offering training or professional development with materials substantially derived from Bootstrap must be approved in writing by a Bootstrap Director. Permissions beyond the scope of this license, such as to run training, may be available by contacting contact@BootstrapWorld.org.